
Machine Learning – The Pinnacle of Modern Statistics!
In my consulting work, during research or while answering student questions, the topic of machine learning pops up constantly. Unfortunately, there are some misconceptions concerning this topic. In this article I am going to explain what machine learning actually is and how you can benefit from those tools.
Machine learning is a collection of modern statistical methods for various applications. Those methods have one thing in common: they try to create a model based on underlying (training) data to predict outcomes on new data you feed into the model. A test dataset is used to see how accurate the model works. Basically Machine learning is the same as Statistical Modelling.
Of course those modelling techniques rely heavily on modern day computer power. Without high speed calculations all those models would not be possible. Therefore machine learning is quite often used by people with informatics background.
One major problem with this approach is overfitting. In this case the model would work very well with the training dataset, but as soon as you put extra test data into the model, the error rate increases severely. There is a higher chance of overfitting in very complex models with many predictor variables, therefore rather simple models with the minimum amounts of variables are to be favoured. This is also where Cross Validation comes in handy.
Let us take a look at some common Machine Learning fields:
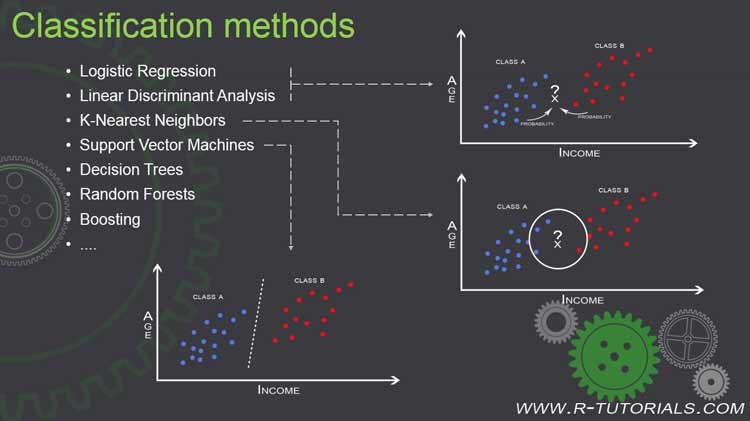
1. Classification: This is probably the most common application of ML. Briefly spoken, you take the underlying variables of an observation and calculate the most likely class this observation belongs to.
The classic example for this are spam filters. You have some text based predictor variables like the amount of keywords (e.g. “discount”, “free”, “offer”, “sale”, …). With this text based training dataset you create a model. By using the model you can predict if a new observation belongs to class “Spam” or not.
Methods used for classification are Support Vector Machines, Logistic Regression, Linear Discriminant Analysis, K Nearest Neighbors.
2. Regression: This is quite similar to classification. When using regression you aim for a continuous outcome (numeric) instead of a qualitative (groups) one.
3. Clustering: At the first glance clustering might be the same as classification. If you take a closer look however, you will see that it aims at putting observations into different groups while there is no grouping variable or factor. Only the predictor variables are used to calculate those classes or groups. This is an unsupervised task whereas classification is supervised since you know the classes before you create the model.
A typical method for that would be the K-means algorithm.
The fields where those models are applied are as manifold as the methods itself. Of course the methods were created in academia, but nowadays they are used in marketing, stock trading, finance or insurance. Basically everywhere data is used to make predictions, machine learning tools can be found.
If you seek a career in a data based field you better get familiar with those methods, because they will only get more important in the future.
Fortunately, the most useful tools are already implemented in standard analytics software. If you take a look at the R machine learning task view, you can see that a wide array of packages is available. The same is true for Python, where those tasks are also performed.
Another very useful and highly specific program is WEKA which is a machine learning software created in New Zealand.
Fortunately, the available modelling software makes it really easy to implement machine learning in your daily work. Even if you do not have an advanced degree in math or stats, you can still benefit from machine learning. Once you understand which functions to use including the according arguments you are ready to go.
Do you already use machine learning tools? Are you planning on implementing them? Just let me know and drop a comment on your experiences.
