
Social Media Analysis in R
Lately I am receiving more and more requests about R and social media analysis. Therefore, I am creating a whole video tutorial on this topic. If you use R’s social media mining tools in a proper way, you can do some very powerful things when it comes to marketing or even investing.
This application of R is not only of scientific interest, even if academia was pushing this topic the last decade.
Let us take a brief look at two fields that can be tackled with social media mining in R:
- How can social media analysis in R help me with investment decisions?
There are several studies indicating that text sentiment highly correlates to stock price performance. Dataminr.com is a classic example of how this kind of information can be used and sold. - How can I use social media mining for my company?
Another very interesting application for that tool would be keyword research for your blog or to gather information on your competition.
As you can see, this form of analysis in R is highly relevant. But in order to be able to perform such an analysis, you need to have an advanced knowledge of R (functions, loops, apply family) and you need to know how to do social media analysis.
Typically, social media analysis can be split into the following 3 steps:
1. Scraping the data
This is the process where you get all the data from the various web platforms into your system. Data can be fetched from social media (Twitter is the most popular one for analysts) or even from the web. In order to be able to get the data you need to connect R with the corresponding platform. Since social media analytics is not a standard R feature, and it surely was not around in the 80s when R was written, you need to load some extra packages in order to interact with the external platforms. Fortunately, there are many teams out there (academic and non-academic) who write those packages, making our life much easier in the process. If you go to the R task view for web technology you can simply scroll down to social media and you will see that there are tons of tools available. In the tutorial I will mainly work with twitteR since it offers tons of info and the data is easily accessible.
2. Mining, cleaning and making the data ready
Only downloading millions of pages does not yield any success if you are not able to structure your data. In this step the corpus (the collected text including the meta-info) is processed, put together in one R readable document (quite often a special type of matrix) and useless text like stopwords or punctuation is removed.
For this step there is a bunch of packages available. You can check out the task view here.
I think the package “tm” or text mining is the most important one. In the video course I will show you which of the many functions of that package are useful for that kind of task. In this stage you will also see the first graphical results like dendrograms or wordclouds.
3. Sentiment analysis
This is the last step of the whole process. Basically you are comparing your corpus with a predefined sentiment lexicon. This can be an art itself and the approaches to it can vary quite a bit. A typical R package would be “sentiment”. But in the course I will show you how you can create your own function in order to do sentiment analysis. If you do sentiment analysis properly, you will get a score with sentiment points. With this score you can than see if people (e.g. from Twitter) have a positive, negative or neutral opinion towards your search term. This can be even carried further to emotion analysis, where your final score shows which emotion your audience associates with your company or product.
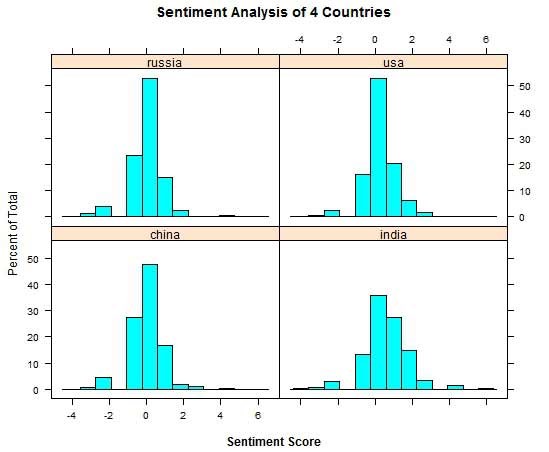
As you can see social media analysis in R is very powerful. If you already have a solid understanding about R, you should definitely take a look at it since its applications are so manifold. No matter if you are doing keyword research for your blog, sentiment analysis for your investment strategy, or you just want to add this skill to your CV for higher employ-ability, R offers some really helpful tools to facilitate social media analysis.
